在人工智能模型不断追求更长上下文理解能力的潮流涌动之际,有一种叫作HySparse的创新架构,因它别具一格的设计,引发业界的关注。它借助巧妙地混合稀疏以及全注意力层,在确保模型性能的情形下,极大程度地降低了长序列处理时所需的高昂计算成本以及存储成本。
架构设计的核心创新

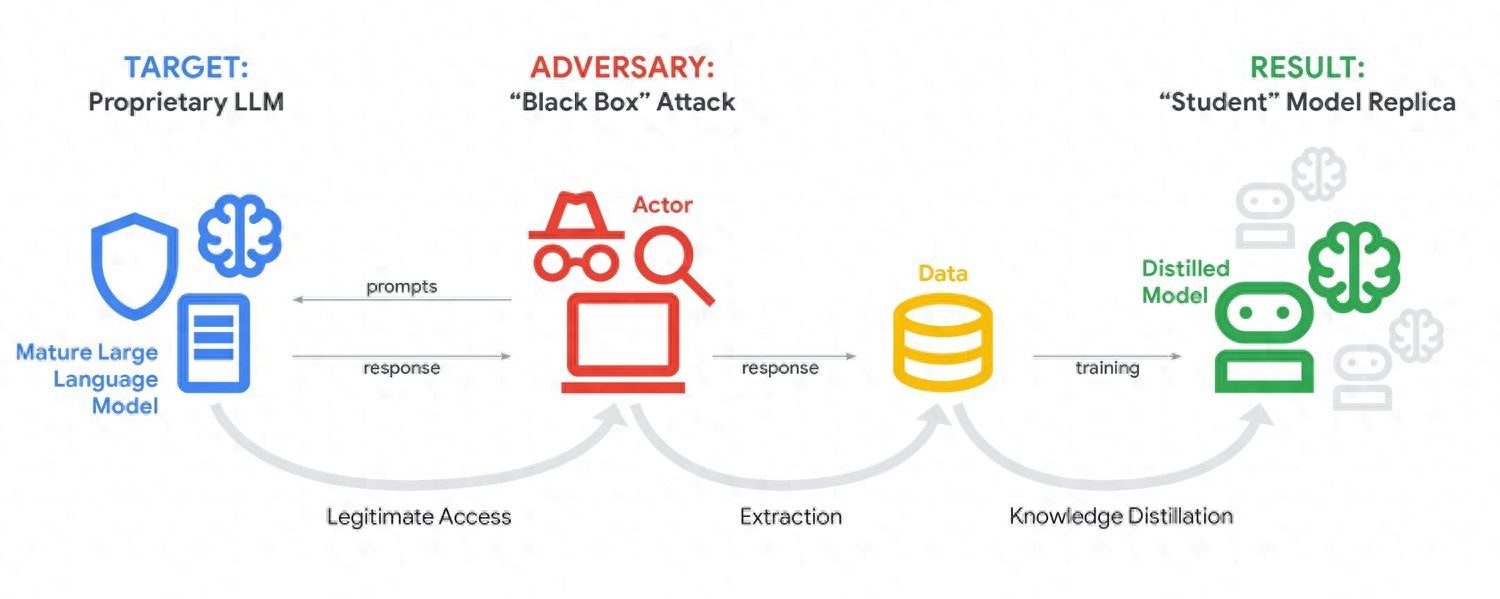
HySparse架构的核心之处在于对注意力机制的任务做了重新分配,它把关键的信息筛选以及缓存工作集中起来,交给极少数的全注意力层去完成,后续有大量的稀疏注意力层,这些稀疏注意力层直接复用那些已经处理好的信息,这样的设计打破了传统稀疏注意力方法里那种“每层都要独立选择重要信息”的固有范式。
具体来讲,于模型的一个混合块当中,处在前方位置的全注意力层会精准地算出当下上下文中全部token所具有的重要性,进而生成与之对应的键值缓存。在其紧挨着的后面,众多稀疏注意力层不用再重复这个过程,能够直接凭借前一层所提供的索引以及缓存来展开高效计算。这样的一种设计从结构方面达成了计算资源的精准投放。
解决稀疏注意力的根本难题
长期以来,传统的动态稀疏注意力方法一直遭遇着实很不小的两大棘手挑战,其一是重要信息选择方面准确性欠缺,其二是键值缓存存储并没有做到显著地减少。虽然计算量已然降低,然而为了能够有效应对生成过程期间信息重要性发生的动态改变,系统一般情况下依旧得留存完整无暇的键值缓存,这无疑就形成了内存方面的瓶颈。
涉及HySparse的混合方案直接就这两个痛点作出了回应,全注意力层付出高计算成本的代价,提供了最为精准的token重要性判断以及完整的初始键值缓存,稀疏层是在这个基础之上展开工作,其本质上规避了因近似选择而引发的误差累积问题,同时因为不需要维护全量缓存,所以显著节省了内存。
混合块内的双层稀疏设计
于混合块的稀疏注意力层里头,HySparse并没有运用单一的计算路线。它的设计将全局稀疏检索、局部窗口注意力这两个分支给融合起来了。全局分支承担着捕捉长距离的依赖关系的职责,而局部分支把重点放在临近token的精细建模上。
一个轻量化的sigmoid门控机制,对两个分支的输出予以动态融合,模型能够自适应地判定,在特定位置更倚赖何种信息。这样一种“全局 + 局部”的二次混合,进一步加大了模型于稀疏计算时的表征能力,保证在削减计算量之际,不会丢失对复杂上下文模式的捕捉。
显著的性能与效率提升
对于总层数为49层的80B MoE模型的实验,研究团队在其中仅保留五层全注意力,成功把键值缓存的存储需求降低了近乎十倍,从而为部署超长上下文模型扫除一个重大障碍,此即在7B稠密模型跟80B混合专家模型之上证实了HySparse的有效性。
在多项标准评测里,其中涵盖通用知识、数学推理、代码生成以及中文理解,采用HySparse架构的模型都呈现出稳定提升之态。尤其是在诸如RULER等针对长文档理解的测试集方面,该架构就算是在激进地减少全注意力层的情形下,依旧能够稳定地维持对长距离关键信息的访问能力。
对现有范式的超越与启示

HySparse的成功不是那种简单的替换,而是针对全局信息通路所进行的系统性的重构,它把原本价格高昂然而可靠的全局注意力计算,跟廉价且高效的全局稀疏检索以及局部建模结合在了一起,这样的思路给后续的架构设计提供了新的方向。
此项工作也证实了,那种跨层共享键值缓存的情况,不仅在理论层面是具备可行性的,并且更是能够产生显著的实践方面的收益。在此之前,像YOCO、Gemma3等之类的研究,已经针对此展开了探索,而HySparse把它应用到混合注意力块之内的定向共享当中,达成了效率与性能的更为优良的平衡。
未来的应用前景与挑战
小米公司里头的MiMo研究团队这么讲,打算于更大规模的模型之上进一步去探寻HySparse的潜力,并且持续不断地去试着减少对于全注意力层的依赖,这就意味着在未来我们有希望看到那种能够处理数百万乃至更长token序列的高效模型,而所需要的计算资源增长将会变得更为平缓。
然而,把这类研究从实验环境推向实际生产,还需要解决一系列问题,比如工程化、稳定性以及在不同任务领域的泛化能力等。下一阶段的研究重点将会是,怎样在极端稀疏配置的情况下,让模型在各种边缘案例上保持鲁棒性。
于当下追求模型能力无限拓展之际,你觉得诸如HySparse这般着重于“增效”而非仅仅“增规”之便技术路线,会不会成为下一代大模型发展之主流趋向呢,欢迎于评论区剖析你的看法。