论文插图,在追求高质量科研成果的激烈竞争里,成了决定性的“软实力”。一项叫PaperBanana的创新技术,近日引发关注,它要通过多智能体协作的AI流程,彻底改变学术界长期被低效绘图工作拖累的现状,还要改变长期被不精准绘图工作拖累的现状。
科研绘图的效率瓶颈
当前,科研人员于制作论文配图之际,存有主要的两种选择。其一为运用LaTeX的TikZ或者Python的Matplotlib等编程绘图工具。尽管它们能够产出精准的矢量图,然而其本质属于几何绘图语言,难以对机器人动作、智能体交互等动态具象概念予以描述,并且通常需要投入数周时间去学习。
存在着另外一种方式,其借助Midjourney、DALL-E这类通用文生图模型,这种方式门槛较低,能够生成视觉吸引力较强的图像,然而却常常因为缺乏领域知识而出现“翻车”情况,这些模型对于箭头代表数据流向、模块位置表明逻辑层级等学术插图所特有的视觉语言规范难以理解,进而致使生成的图片与论文内容出现脱节。
从语义推断到参考驱动
PaperBanana的核心创新之处在于,将任务范式从“语义推断像素”进行了重构,使其成为“参考驱动”的多智能体协作,这模拟了人类研究者的真实工作流程,此流程为,设计配图的时候,会再三对同类顶尖论文的视觉范式予以参考,而不是毫无依据地去创造。
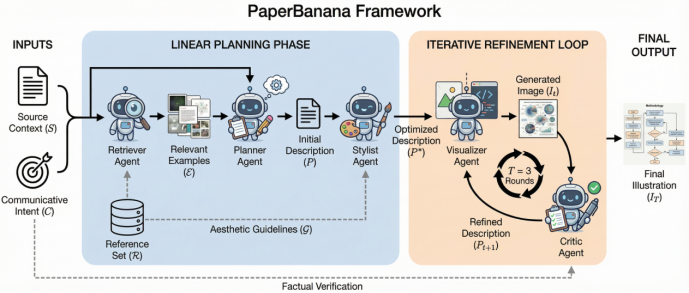
此项技术搭建起一条流水线,其中含有具备五个专业化特质的智能体,它们各自承担着不同职责,一个负责检索参考范例,一个负责规划生成逻辑,一个负责制定美学规范,一个负责生成图像雏形,还有一个负责开展系列轮次的批评以及迭代优化行为,如此这般的分工以协同合作的方式,意在系统性地去处理通用模型于专业场景之内所存在的知识方面的不足缺陷状况。
五智能体协作流程详解
在用户输入方法描述以及图注以后,首个智能体“检索师”遂开始展开工作,它会于图库内寻觅风格以及结构最为相似的参考图,优先去匹配流程图、架构图之类的视觉拓扑结构,并非仅仅是单纯的主题关键词,举例而言,在为“多智能体推理框架”配置图片的时候,系统会检索具备并行分支、信息聚合结构的图表。
“设计师”智能体,从检索出的范例里,借由上下文学习,提炼出一套绘图逻辑,把非结构化的文本,转化成详细的视觉描述。之后,“艺术指导”会依据学术期刊的审美规范,制定字体、配色、布局等具体的美学指南,给后续生成设确定约束。
生成、批评与迭代优化
接收前序智能体发来指令的 “渲染师”,调用图像生成模型产出初稿。而后开启工作步骤的 “批评家”,会基于视觉语言模型对初稿展开多维度评估。测试数据表明,倘若缺失此类经过好多轮来进行的反馈机制,配图忠实度将会下降8.5%。
这种迭代优化机制保证了技术细节的精确性不会因视觉上的简化而被舍弃,整个流程展现出当前 AI 应用从单模型、单任务朝着多智能体协作发展的关键趋向,凭借专业化分工达成了效率与质量的均衡。
严谨的评估与显著成效
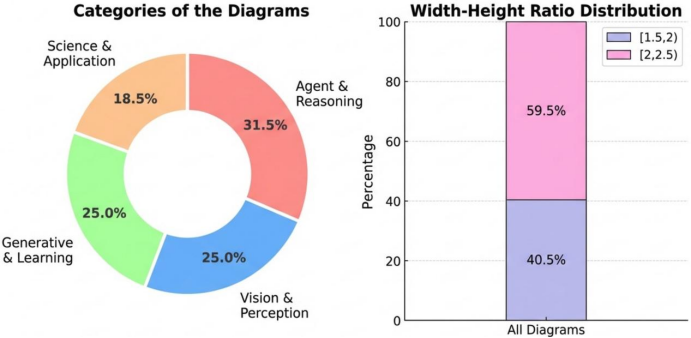
那研究团队,是照着NeurIPS 2025有着的5275篇论文去做系统地采样处理,最终,得到了292个高质量的测试用例,这些测试用例覆盖了智能体推理、视觉感知等好些个前沿领域。而后,他们选用视觉语言模型当作“裁判”,针对AI生成图以及人类绘制图开展双盲对比评分。
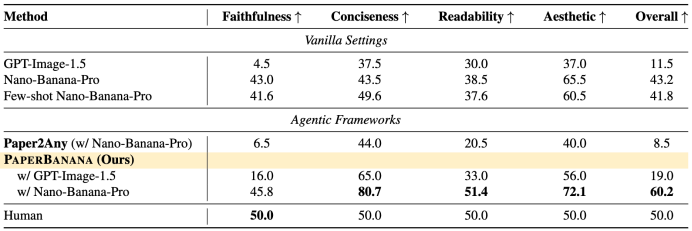
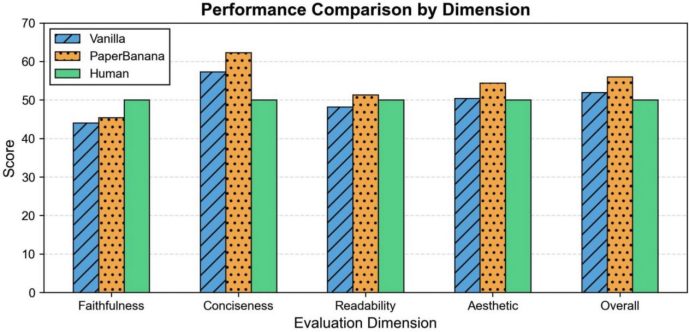
评估是围绕技术忠实度、简洁性、美观度以及整体可用性这四个维度来展开的。结果表明,在292个测试案例之中,PaperBanana的综合胜率达到了59.7%。其中,简洁性的提升是最为显著的,达到了37.2%。除了忠实度之外,其余三个维度的得分均已经超越了人类绘制的参考配图水平。
技术局限与未来展望
即便已有显著成效,PaperBanana却依旧存有局限,举例来说,于测试期间察觉到了些许技术性错误,像是错误的数据流向或者标签缺失,这暴露出当下视觉语言模型对于像素级视觉关系的感知能力仍有所欠缺 ,此自动化配图不单单是生成方面的问题,更是深度的视觉理解层面的问题。
研究团队宣称,往后的规划是把OCR以及SAM3技术联合起来开展元素级别的重构,又或者训练GUI Agent直接经由操作专业软件去生成原生矢量图。这项技术的参考驱动和风格归纳范式拥有显著的可扩展性,其核心理念有希望为多种专业图像生成场景提供普遍的解决办法。
您觉得,当AI工具助力研究者摆脱繁琐事务得以解脱之际,怎样进行设计方能更优地服务于人类创造性思维而非将其取代呢?欢迎于评论区分享您的看法,要是认为本文具备价值,请点赞予以支持。